Research-First Evaluation OS
RLM Code
Research Playground for Recursive Language Models
Run real RLM workflows, benchmark them, replay every step, and compare results under controlled budgets and secure sandboxes.
Open source under Apache-2.0. Explore the project on GitHub.
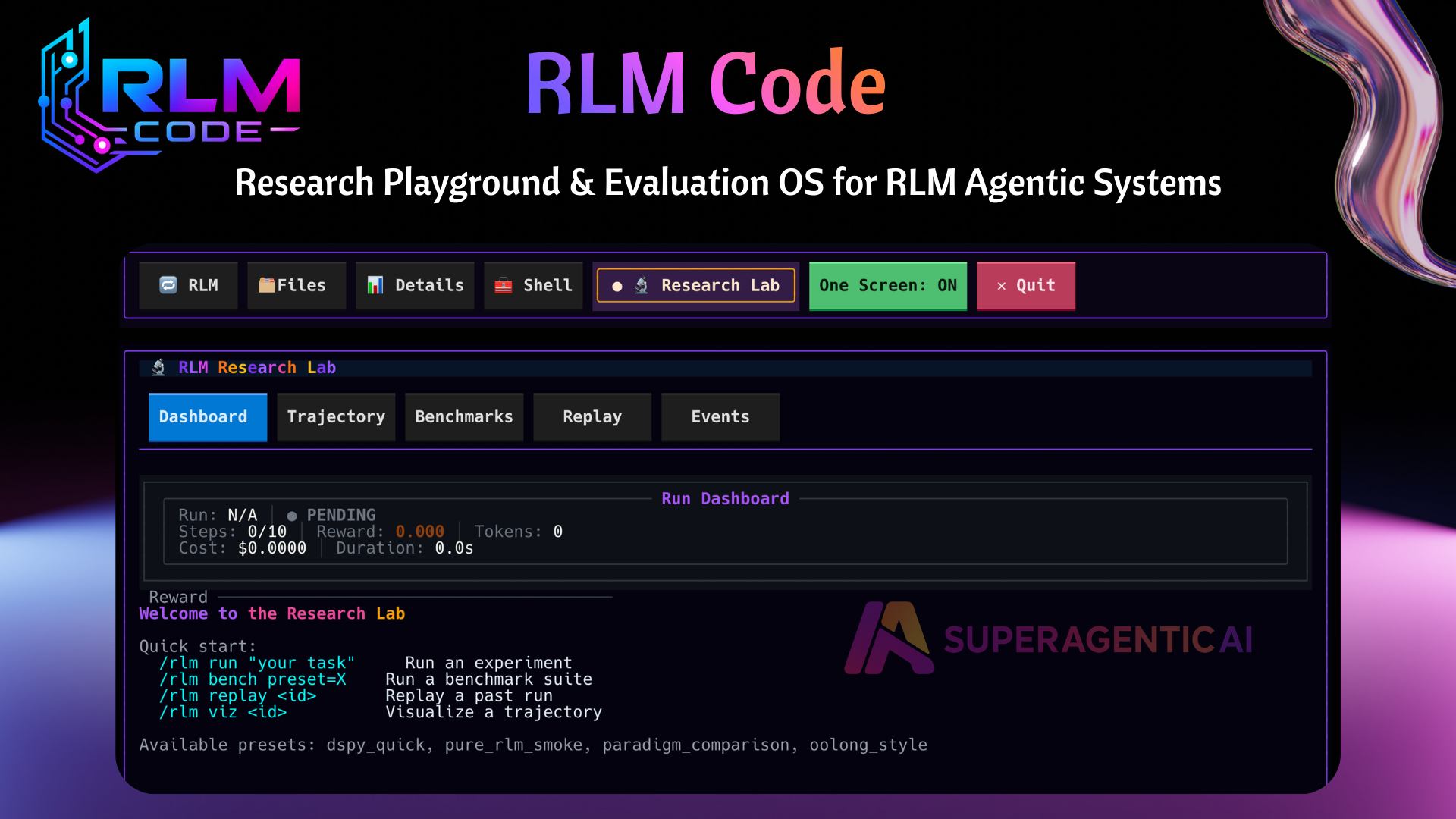
Is RLM revolutionary or just another coding agent?
The debate is active. RLM Code gives researchers a way to test claims directly with reproducible runs, benchmark comparisons, trajectory replay, and cost and token tracking.
You do not need to pick a side first. You can run the same tasks, inspect the traces, and decide with evidence.
Use your preferred stack
Mix runtimes, framework adapters, and observability tools without changing your research workflow.
Runtimes
Frameworks
Observability
Code Mode support
RLM Code supports Code Mode-style MCP workflows for research and benchmarking. In the current release, use strategy=codemode with UTCP and strategy=tool_call with Cloudflare remote MCP.
UTCP local MCP
Best fit for direct Code Mode contract in this release.
>/mcp-connect utcp-codemode>/mcp-tools utcp-codemode>/harness run "analyze this repo, find TODO/FIXME, and create report.json" steps=3 mcp=on strategy=codemode mcp_server=utcp-codemodeCloudflare remote MCP
Use tool-call strategy when remote tool naming differs from Code Mode bridge contract.
>/mcp-connect cloudflare-codemode>/mcp-tools cloudflare-codemode>/harness run "list available tools and run one safe read-only action, then summarize in 3 bullets" steps=3 mcp=on strategy=tool_call mcp_server=cloudflare-codemodeCode Mode docs: superagenticai.github.io/rlm-code/codemode/
Reference: Cloudflare Code Mode MCP and the RLM Code technical deep dive. Watch the walkthrough video: RLM Code demo on YouTube.
Built for research workflow
Implementation friction: get a runnable RLM loop without custom scaffolding
Experiment management: run, compare, replay, and export results in one place
Security controls: use secure runtime profiles and explicit unsafe opt-ins
Reproducibility: keep traces, metrics, artifacts, and benchmark history
Operational visibility: inspect events, rewards, tokens, and runtime health
What is included
Core capabilities for running reproducible RLM experiments end-to-end.
Research Lab TUI
Dashboard, Trajectory, Benchmarks, Replay, and Live Events in one focused interface.
Benchmark System
Built-in benchmark presets, leaderboard metrics, run comparison, and report export.
Session Replay
Step through decisions and outcomes to inspect behavior, not just final answers.
Superbox Sandbox Layer
Policy-based runtime selection and fallback across Docker, Apple Container, and cloud runtimes.
Framework Adapter Registry
Compare execution across DSPy RLM, ADK, Pydantic AI, Google ADK, and DeepAgents.
Observability Integrations
Connect MLflow, Logfire, LangSmith, LangFuse, OpenTelemetry, and local JSONL sinks.
Code Mode MCP Support
Run Code Mode-compatible workflows with MCP backends, including UTCP local and Cloudflare remote paths.
Watch RLM Code in action
Install, connect, run a bounded RLM task, benchmark, compare, and inspect replay in the Research Lab.
From install to measurable result in minutes
$uv tool install "rlm-code[tui,llm-all]"$rlm-code>/connect>/sandbox profile secure>/rlm run "small scoped task" steps=4 timeout=30 budget=60>/rlm bench preset=token_efficiency>/rlm bench compare candidate=latest baseline=previous>/rlm observabilitySafe and bounded by design
Secure profile sets Docker-first execution defaults
Unsafe exec mode requires explicit acknowledgment
Step, timeout, and budget controls prevent runaway runs
/rlm abort allows immediate cancellation
Runtime doctor and status commands expose readiness and misconfigurations
Research-first audience
Who it is for
- Researchers evaluating long-context reasoning methods
- Applied AI teams validating execution patterns before product rollout
- Framework authors testing adapter behavior in a unified benchmark harness
Not the primary target
- One-click consumer chat workflows
- Unbounded autonomous production agents without evaluation controls
FAQ
Can I use MLflow and Logfire at the same time?
Yes. Multiple observability sinks can run together.
Can I compare RLM with other execution paradigms?
Yes. Run benchmarks and compare runs with consistent bounds and metrics.
Can I use local models?
Yes. Local and BYOK routes are supported.
Is secure execution required?
For serious experiments, yes. Use secure sandbox profiles by default.
Stop arguing. Run the experiment.
Use RLM Code to test what works for your tasks, constraints, and models.