Why this release matters
Long-context reasoning is where many agent systems become expensive, brittle, or hard to interpret. Traditional patterns often keep appending text into context windows and summarizing aggressively. RLM-style methods propose a different pattern:
- Treat long context as symbolic data in the environment.
- Have the model write code that recursively calls LMs for subproblems.
- Return subcall results into variables, not into ever-growing chat history.
Whether that is revolutionary or incremental should be measured on real tasks with repeatable traces. RLM Code gives you that workflow.
What RLM Code is
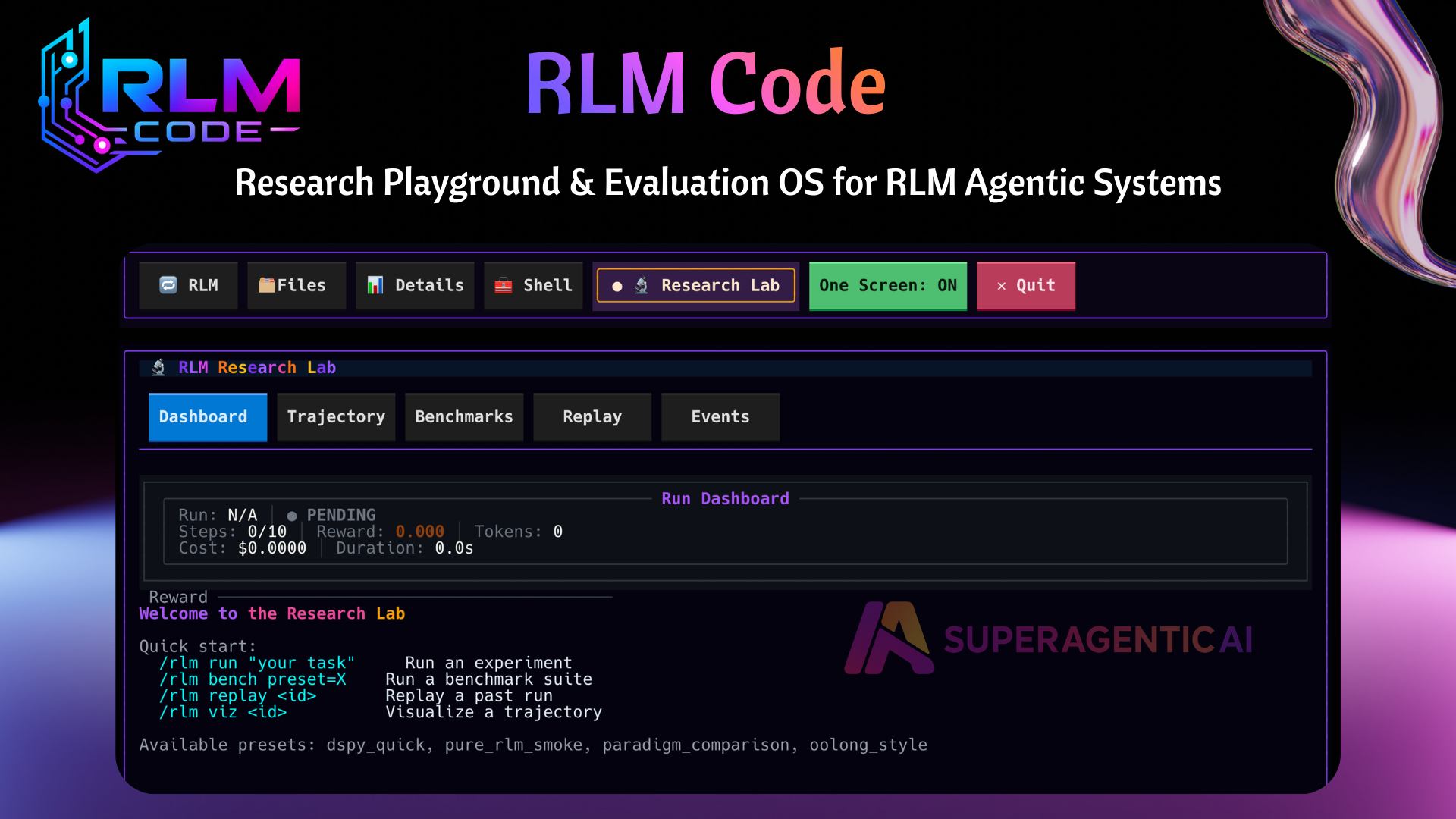
RLM Code is a research playground and evaluation OS for recursive language-model workflows. It is built for researchers and builders who need reproducibility, trajectory visibility, and controlled comparisons across execution styles.
What is included
1. Research-first TUI
A dedicated Research Lab tab with:
- Dashboard
- Trajectory viewer
- Benchmarks
- Replay
- Live events
2. Benchmark system
Built-in presets (including paper-oriented styles), leaderboard metrics, comparison reports, and artifact export.
3. Sandbox runtime layer (Superbox)
Runtime selection and fallback across:
- Docker (recommended secure default)
- Apple Container (macOS)
- cloud options like Modal, E2B, Daytona
- Local only for development
Pure exec is explicit opt-in with acknowledgment.
4. Framework adapter registry
Adapter-ready execution for:
- DSPy RLM
- ADK-style RLM paths
- Pydantic AI
- Google ADK
- DeepAgents
5. Observability integrations
Pluggable sinks for:
- Local JSONL
- MLflow
- OpenTelemetry
- LangSmith
- LangFuse
- Logfire
You can run multiple sinks at once and verify from TUI.
Product demo
A practical way to evaluate RLM vs coding agents
- Fix the same benchmark/task set.
- Keep model families and budget constraints comparable.
- Use bounded runs for steps, timeout, and budget.
- Compare trajectories and final outcomes together.
- Track failure modes and tail behavior, not only averages.
RLM Code is designed to make this protocol straightforward, reproducible, and auditable.
Security and runtime posture
Secure execution is a first-class requirement. Runtime selection and fallback are policy-based across Docker, Apple Container, Modal, E2B, Daytona, and local dev mode. Pure exec requires explicit acknowledgment.
Recursive workflows can scale compute quickly, so set boundaries before broad experiments: steps, timeout, and budget.
Getting started
Install, launch, and run your first bounded workflow:
$uv tool install "rlm-code[tui,llm-all]"$rlm-code>/connect>/sandbox profile secure>/rlm run "small scoped task" steps=4 timeout=30 budget=60>/rlm bench preset=token_efficiency>/rlm bench compare candidate=latest baseline=previous>/rlm observabilityResources
- Docs: https://superagenticai.github.io/rlm-code/
- PyPI: https://pypi.org/project/rlm-code/
- GitHub: https://github.com/SuperagenticAI/rlm-code
This release is not asking you to accept a claim by branding. It asks you to run experiments. If RLM patterns deliver real advantages for your workload, you should be able to prove it with traces and benchmarks. If they do not, you should be able to show that clearly too.